

With today’s advancement of technology that allows for mass data collection, data-driven decision-making has become the norm. From machine learning, data science, and advanced analytics to real-time dashboards, decision-makers are gathering data to help them make the best decisions.
Modern businesses have a vast amount of data that they want to use in as many ways as possible. This is where data lakes come into play. A data lake can serve as a repository that accommodates multiple data-driven projects. In this article, we’ll explain what data lakes are, their pros and cons, when they are used, and many other aspects of this powerful technology. Let’s dive in!
What is a Data Lake?
A data lake is a repository that enables you to store all the structured and unstructured data you collected at any scale. You can store your data as-is with data lakes without having first to structure the data. Data lakes allow you to run different types of analytics, from visualizations and dashboards to big data processing, real-time analytics, and machine learning that can help you make better decisions.

A data lake consists of four primary components: storage, format, compute, and metadata layers.

Data Lake Advantages and Disadvantages
Data Lake: Pros
Data lakes are more suited for analyzing data from diverse sources, especially when the initial cleaning of data is resource-intensive or problematic.
Here are the advantages of data lakes.
- Volume and Variety. A data lake can house large amounts of data that Big Data, artificial intelligence, and machine learning often require. Data lakes can also handle the volume, variety, and velocity of data that come from various sources and ingest data in any format.
- Speed of Ingest. Data lakes can ingest data quickly because the format is irrelevant during ingests. Data lakes use schema-on-read Instead of schema-on-write, meaning data doesn’t need to be processed until needed.
- Lower Costs. Data lakes can be significantly cheaper when it comes to storage costs. This enables companies to collect a wider variety of data, even unstructured data such as rich media, email, social media, or sensor data from the Internet of Things (IoT),
- Greater Accessibility. Data lakes make opening copies or subsets of data that different users or user groups can access easily. Companies can provide broader access to their data while keeping their data access in control.
- Advanced Algorithms. Data lakes allow companies to conduct complex queries and run deep-learning algorithms to recognize patterns.
Data Lake: Cons
Despite their many advantages, data lakes are not perfect, and there are some downsides to them, often depending on your data storage and data analysis needs. Disadvantages of data lakes are:
- Complex On-Premises Deployment: Building a data lake in the cloud is simple, but building one in an on-premises infrastructure can be significantly more complex. On-premises solutions for data lakes, such as Hadoop or Splunk, are available, but data lakes are built for the cloud.
- Learning Curve: Data lakes require learning curves, new tools, and new services, so you will need to get either outside help, training, or recruit a team with data-lake skills.
- Migration: If you’re already operating with data warehouses, transitioning to data lakes takes some careful planning to preserve your data sets.
- Handling Queries: It’s fast and easy to ingest data with data lakes, but they are not optimized for queries in the way data warehouses are. Employing practices for database queries can help, but data retrieval with data lakes is not as straightforward as it is with data warehouses. In a data lake, data is processed after it has been loaded with the Extract, Load, Transform (ELT) process.
- Risk of data swamps. Semantic consistency, governance, and access controls are required, otherwise, a data lake may turn into a “data swamp” of unusable raw data.
How to Build a Data Lake?
To build a data lake, first, data needs to be landed in a highly-available storage service. The data should be stored as is in its native format before being processed into a different format for analysis.
The next step is connecting a computing engine such as Presto or Spark to run computations on the data, which creates a working minimally viable data lake. From here, you can take further steps to optimize storage patterns by partitioning and applying schema validations to improve the lake’s functionality.
Data Lake Tools and Providers
There are a variety of tools that can be combined to create data lakes. Once a data lake has usable data assets, it becomes available for use.
- Storage: The storage service of major cloud providers, including AWS S3, Google Cloud Storage (GCS), and Azure Data Lake Storage (ADLS), is most commonly used for a data lake’s storage layer. There’re a number of other storage providers, both managed and open-source, that are also capable of supporting a data lake, such as IBM Cloud Storage, Alibaba Object Storage, and Oracle Cloud Storage.
- Data Format: The most common formats data lakes support are JSON and CSV. More specialized formats specifically designed for specific use cases of data lake also exist, such as Parquet, Delta, Avro, Iceberg, and Hudi. These formats improve the efficiency of lake operations and make functionalities such as transaction atomicity and time travel possible. Unstructured data formats primarily associated with media-rich images, videos, and audio files are common in data lakes.
- Compute: A vast number of compute engines are available to run operations on data distributed in a data lake. Examples are MapReduce and Hadoop, managed services such as AWS Athena, Google Cloud Dataproc, Azure HDInsight, and applications such as Spark and Presto.
- Metadata. Data-about-the-data, or metadata, in a lake is as important as the data itself is, or metadata, in a lake. Tools such as Hive, AWS Glue, and DataProc Metastore maintain information about partitions and schema to provide structure.
- Clients & Libraries: There are countless clients and libraries that can access data in a lake through JDBC/ODBC and other data-transfer interfaces. The universality of the S3 API (and some other similar storage services) means that almost every coding language, BI Tool, and SQL client can consume data lakes.
Use Cases of Data Lake
Data lakes are suitable for analytics initiatives. Some common examples of their use cases are:
- Data-in-place Analytics: Once you land data in a lake, you won’t need to move it elsewhere for SQL-based analysis. Analysts can run queries on this data to identify trends and calculate metrics regarding the business.
- Machine Learning Model Training: Machine learning usually needs large volumes of data for training to optimize its parameters and achieve high accuracy. Data lakes enable repeatedly generating training and testing loops for data scientists to optimize machine learning models.
- Archival and historical data storage: You can use data lakes as storage for archiving historical data.

Challenges of Data Lakes
Data lakes are susceptible to some common challenges because the ecosystem around them is relatively new, and some technologies used are still maturing.
Small Files: One challenge is the “small file” problem that occurs when a large number of files — each with a small amount of data — come into a data lake. The issue with small files is that they are inefficient for running computations. The answer to the small file problem is running periodic maintenance jobs that compact small data packs into the ideal size for efficient analysis.
Partitioning and Query Efficiency: Data lake assets can be optimized for filtering or aggregation on certain fields by employing partitioning. Partitioning is the physical organization of data by a specific field or a set of fields on blob storage. A user can incur high costs and wait times from running queries that aren’t suitable for a table’s partition structure.
The Shared Drive: Without proper governance, data lakes can easily resemble a shared folder in which multiple people leave files without consideration for the intended requirements of other users. Thoughtful data lake workflows and proper governance are necessary to prevent a data lake from becoming a data swamp.
Data Lakes vs Data Warehouses.
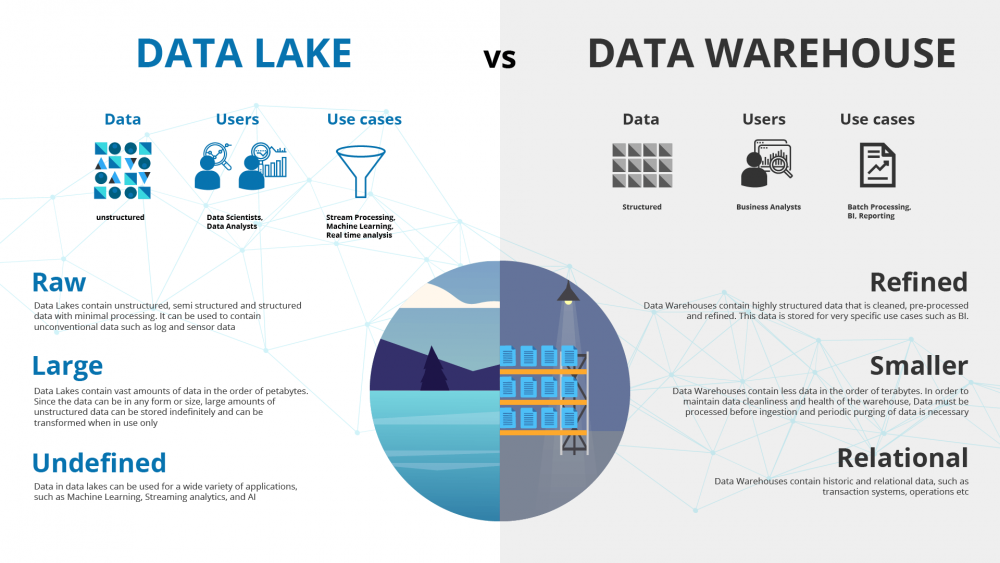
A typical organization often uses both data warehouses and a data lake as they serve different needs.
A data warehouse is a database optimized for analyzing relational data coming from transactional systems and business applications. The data structure and schema are determined in advance to optimize for fast SQL queries, and the results are often used for operational analysis and reporting. Data in a data warehouse is cleaned, processed, and organized so it can become the “single source of truth” that users can refer to.
Data lakes are different because they store relational data from business applications and non-relational data from IoT devices, mobile apps, and social media. The structure of the data is not defined when it is captured. This means you can store all of your data in a data lake without careful organization or the need to know what questions you’ll have to use the data for in the future. As organizations that are using only data warehouses start to see the benefits of data lakes, they are bringing data lakes into their arsenals and using diverse query capabilities, data science use cases, and advanced capabilities to discover new information models.
Data Lake Vendors
The Apache Software Foundation developed Hadoop, Spark, and various other open-source technologies that are today used in data lakes. These open-source tools can be downloaded and used for free, but commercial vendors offer versions of many of the open-source technologies and offer technical support to their customers. Some vendors even develop and sell proprietary data lake software. There are various data lake technology vendors on the market today who provide platforms and tools to help users build and manage data lakes. Some major vendors are:
- AWS. Apart from Amazon EMR and S3, AWS has supporting tools such as AWS Lake Formation for deploying data lakes and AWS Glue for data preparation and integration.
- Cloudera. The Cloudera Data Platform can be deployed on a public cloud or a hybrid cloud, and it comes with a data lake service.
- Databricks. Founded by Spark’s creators, Databricks offers a cloud-based data lakehouse platform that mixes elements of both data lakes and data warehouses.
- Google. Google combines Dataproc and Google Cloud Storage with Google Cloud Data Fusion for data integration. It also provides services for migrating on-premises data lakes to the cloud.
- Microsoft. Along with Azure Blob Storage and Azure HDInsight, Microsoft offers Azure Data Lake Storage Gen2, a repository that incorporates a hierarchical namespace to Blob Storage.
- Oracle. The Oracle cloud-based data lake technologies offer a big data service for Spark and Hadoop clusters and data management tools.
- Qubole. The cloud-native Qubole data lake platform offers data management, engineering, and governance capabilities and provides various analytics applications.
- Snowflake. While Snowflake is best known as a cloud data warehouse vendor, its platform also supports data lakes and can work with data in cloud object stores.
Final words
Data lakes bring about a lot of benefits that help organizations manage and use their data more effectively. We hope this article has provided you with valuable information about data lakes.



